
La Guerra tra AI e Frodi Finanziarie: Uno Sguardo al 2025
L’intelligenza artificiale sta cambiando le regole del gioco nella sicurezza finanziaria, ma le istituzioni tradizionali faticano ad adeguarsi ai nuovi sistemi di protezione
Siamo arrivati alla fine del 2025 con una consapevolezza che, per chi lavora nel backend dei sistemi finanziari, era chiara da almeno un decennio: la sicurezza basata su regole statiche è morta.
Se guardiamo oltre i comunicati stampa trionfalistici che celebrano l’intelligenza artificiale come il “salvatore” dei nostri conti correnti, emerge un quadro molto più complesso, simile a una partita a scacchi giocata a velocità supersonica dove entrambe le parti – difensori e attaccanti – utilizzano lo stesso identico motore di calcolo.
La notizia non è tanto che l’AI stia “salvando” gli utenti, quanto il fatto che senza di essa l’intero ecosistema delle transazioni digitali collasserebbe sotto il peso della sua stessa evoluzione.
Fino a pochi anni fa, i sistemi antifrode erano essenzialmente enormi elenchi di istruzioni if-then: se un utente spende mille euro in Nigeria alle 3 di notte e risiede a Milano, blocca la carta. Era un approccio deterministico, logico, ma terribilmente ingenuo.
Oggi, i vettori d’attacco sono cambiati radicalmente. I truffatori non cercano più di indovinare la password; utilizzano reti neurali generative per simulare comportamenti umani, clonare voci e aggirare i controlli biometrici.
La fine dell’era delle regole statiche
L’evoluzione tecnica che stiamo osservando è il passaggio dalla verifica dell’identità alla verifica dell’intento. I sistemi moderni di prevenzione delle frodi (quelli che definiamo di “Fase 3”) non si chiedono più solo “Chi è questo utente?”, ma “Come si sta comportando questo utente?”.
È una distinzione sottile ma cruciale che richiede una potenza di calcolo che solo il Deep Learning può offrire. Non si tratta più di analizzare i metadati della transazione, ma di processare in tempo reale migliaia di segnali biometrici comportamentali: la velocità di digitazione, l’inclinazione dello smartphone (grazie ai dati del giroscopio), i micro-movimenti del mouse che differenziano un umano da un bot, o persino la latenza di rete specifica di una connessione residenziale rispetto a quella di un data center usato per il routing del traffico.
È un’architettura elegante perché sposta il campo di battaglia su un terreno dove l’emulazione è computazionalmente costosa per l’attaccante.
Tuttavia, l’implementazione di queste tecnologie non è uniforme. Mentre le fintech native digitali integrano questi modelli nel core delle loro piattaforme, le istituzioni tradizionali faticano ad abbandonare i sistemi legacy. I dati parlano chiaro: già nel 2023 un report di DigitalOcean ha evidenziato come il 37% delle aziende abbia aumentato la spesa in cybersecurity per integrare strumenti avanzati di AI, segnando l’inizio di una corsa agli armamenti che oggi raggiunge il suo apice.
Ma spendere non significa necessariamente risolvere, specialmente quando il nemico ha accesso alle tue stesse armi.
L’asimmetria della minaccia sintetica
Il vero punto di svolta del 2025 non è la difesa, ma l’attacco. L’accessibilità di modelli LLM (Large Language Models) e generatori audio ha democratizzato la frode sofisticata. Non serve più essere un hacker esperto in social engineering; basta un abbonamento a un servizio API per generare script di phishing contestuali o clonare la voce di un CEO.
Sam Altman, CEO di OpenAI, ha recentemente sollevato un punto critico riguardo a questa escalation, sottolineando come la tecnologia abbia superato le barriere di sicurezza tradizionali:
Ho una grave preoccupazione riguardo alla capacità dell’AI di replicare le voci, che ha ormai superato le capacità attuali di difesa e consente uno sfruttamento senza precedenti nelle truffe.
— Sam Altman, CEO di OpenAI
Questa dichiarazione non è allarmismo, ma una presa d’atto tecnica.
I sistemi bancari che si affidano ancora alla verifica vocale o a semplici controlli biometrici statici sono, di fatto, obsoleti. Le statistiche sono impietose: l’82% dei tentativi di frode attuali coinvolge elementi di impersonificazione guidati dall’AI, come i deepfake. La risposta normativa e istituzionale cerca di tenere il passo, tanto che la Federal Trade Commission ha segnalato un netto aumento delle truffe basate su deepfake utilizzati per falsificare le identità.
Il problema tecnico qui è l’asimmetria. Per un difensore, il costo di un “falso positivo” (bloccare un utente legittimo) è altissimo in termini di reputazione e attrito operativo. Per un attaccante che usa script automatizzati, il costo di un tentativo fallito è prossimo allo zero.
Questo squilibrio economico costringe le banche a tarare i propri algoritmi su soglie di tolleranza che, paradossalmente, lasciano passare le frodi più sofisticate per paura di bloccare l’operatività quotidiana.
Il paradosso dell’adozione
Qui arriviamo al nodo cruciale della questione, spesso ignorato dai media generalisti. Se la tecnologia esiste ed è efficace, perché le frodi continuano ad aumentare?
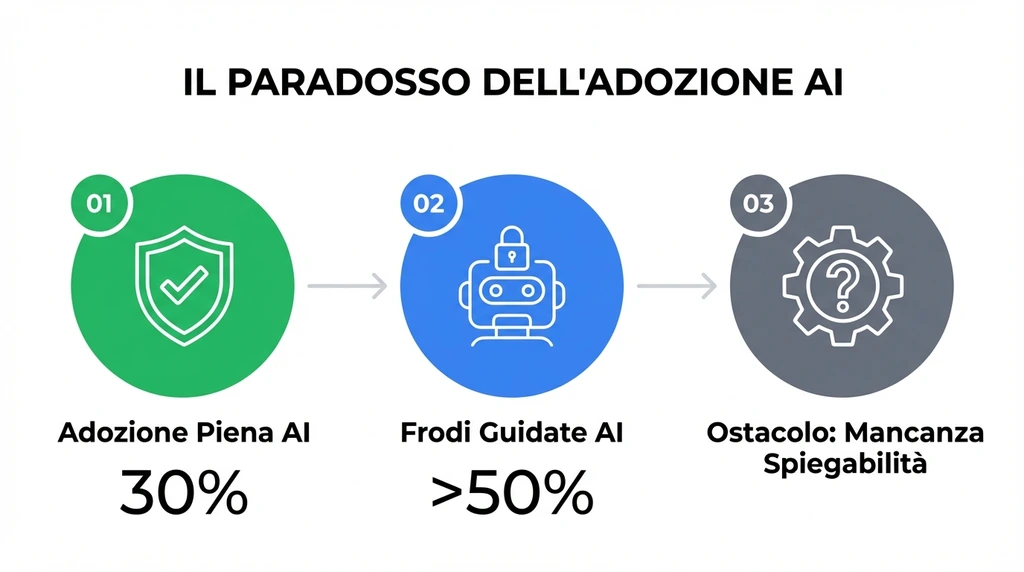
La risposta risiede nell’inerzia infrastrutturale e nella complessità dell’integrazione. Secondo i dati attuali, solo il 30% delle istituzioni finanziarie utilizza pienamente sistemi di prevenzione guidati dall’AI, con quasi la metà del settore ancora indecisa o in fase di test.
Questa lentezza è letale in un ambiente dove oltre il 50% delle frodi finanziarie registrate a ottobre 2025 sia ormai guidato dall’intelligenza artificiale.
C’è una resistenza tecnica fondata: i modelli di Machine Learning sono spesso “black boxes”. Per un ente regolatore o un auditor interno, è difficile accettare che una transazione sia stata bloccata perché “la rete neurale ha rilevato un’anomalia nel vettore di embedding del comportamento utente” senza una spiegazione deterministica chiara. La mancanza di “explainability” (spiegabilità) dell’AI è oggi il più grande freno alla sua adozione massiva nei settori critici.
Inoltre, c’è un aspetto di sovranità dei dati. Affidarsi a fornitori terzi per l’analisi comportamentale in tempo reale significa esporre flussi di dati sensibili, creando nuovi potenziali punti di vulnerabilità. La soluzione ideale – modelli open source trasparenti e on-premise – si scontra con la necessità di avere dataset globali enormi per addestrare efficacemente gli algoritmi, dataset che solo i grandi player proprietari possiedono.
Siamo quindi di fronte a una tensione irrisolta. Da un lato, la necessità tecnica di adottare sistemi predittivi e comportamentali per contrastare attacchi sempre più “umani” nella loro esecuzione; dall’altro, la rigidità di un sistema bancario costruito su paradigmi di controllo del secolo scorso.
La domanda che dovremmo porci non è se l’AI riuscirà a fermare tutte le frodi, ma quanto margine di errore siamo disposti ad accettare in un mondo in cui distinguere un cliente reale da una sua copia sintetica è diventato matematicamente impossibile per l’occhio umano?


