
OpenAI e il raddoppio dei limiti Codex: Un regalo di Natale o una trappola per i dati?
Dietro il raddoppio dei limiti di utilizzo di Codex si nasconde una strategia per ottenere dati e feedback utili al perfezionamento del modello GPT-5.2, sollevando interrogativi sulla privacy e la sicurezza dei dati.
È l’ultimo giorno dell’anno e, mentre stappate lo spumante e cercate di dimenticare le scadenze lavorative, nella Silicon Valley qualcuno sta lavorando sodo per assicurarsi che il vostro riposo sia produttivo.
Per loro, s’intende.
OpenAI ha deciso di chiudere il 2025 con un gesto che, a una lettura superficiale, potrebbe sembrare pura generosità natalizia: un raddoppio dei limiti di utilizzo per i suoi utenti Codex.
Ma chi si occupa di privacy e sorveglianza digitale sa bene che nel mondo delle Big Tech non esistono regali, esistono solo incentivi all’uso.
Dietro la facciata del “buone feste”, si nasconde un bisogno disperato di dati, feedback e validazione per la loro ultima creatura, il GPT-5.2-Codex, rilasciato in fretta e furia poche settimane fa. La domanda che dovremmo porci non è come sfruttare questi crediti extra, ma perché OpenAI abbia così tanta fretta di farci lavorare gratis sui loro sistemi proprio mentre dovremmo essere in ferie.
Il cavallo di Troia “agentico”
Il 18 dicembre scorso, l’azienda di Sam Altman ha lanciato quello che definisce il suo modello più avanzato per l’ingegneria del software.
Non stiamo parlando di un semplice chatbot che suggerisce snippet di Python. GPT-5.2-Codex è un modello “agentico”: è progettato per agire, prendere decisioni, eseguire refactoring su interi repository e maneggiare il terminale.
Per spingere l’adozione di questa tecnologia invasiva, il responsabile dell’ingegneria del codice ha annunciato il reset dei limiti di utilizzo fino al primo gennaio.
Per gli utenti Codex, per ringraziarvi tutti del divertimento che abbiamo avuto negli ultimi mesi, il nostro primo regalo è che abbiamo resettato i limiti di velocità e stiamo portando i limiti di utilizzo al doppio del normale fino al 1° gennaio. Auguro a tutti voi buone feste e tanto coding!!
— Thibault Sottiaux, Code engineering lead presso OpenAI
Analizziamo il sottotesto.
Rilasciare una tecnologia agentica significa chiedere agli sviluppatori di concedere all’IA un accesso senza precedenti ai propri ambienti di sviluppo. Per addestrare e affinare questi agenti, OpenAI ha bisogno di vedere come sbagliano, come si correggono e come interagiscono con codebase reali e complesse.
Il “regalo” è, in realtà, un massiccio stress-test distribuito.
Ogni volta che accettate il suggerimento di un agente che ristruttura il vostro codice, state fornendo dati preziosi per un modello il cui modello di business è, paradossalmente, rendere obsoleta la vostra professione. E lo state facendo gratis, anzi, pagando l’abbonamento Plus o Team.
Ma c’è un aspetto ancora più inquietante che riguarda la sicurezza dei dati. Quando permettiamo a un “agente” di operare autonomamente, dove finisce la responsabilità e dove inizia la negligenza?
Cybersecurity o insicurezza automatizzata?
L’aspetto più critico di questo rilascio riguarda le capacità di cybersecurity del nuovo modello. OpenAI sostiene che GPT-5.2-Codex sia in grado di difendere le infrastrutture meglio di qualsiasi predecessore, ma ammette candidamente l’esistenza di rischi enormi. È la classica retorica della “doppia faccia” della tecnologia: lo stesso strumento che ripara una falla può essere usato per trovarne una e sfruttarla.
Pochi giorni fa, OpenAI ha rilasciato ufficialmente GPT-5.2-Codex, definendolo il modello di coding agentico più avanzato. Tuttavia, nelle pieghe dei comunicati stampa, emerge una preoccupazione che dovrebbe far saltare sulla sedia qualsiasi Garante della Privacy europeo.
GPT‑5.2-Codex possiede capacità di cybersecurity più forti di qualsiasi modello che abbiamo rilasciato finora. Questi progressi possono aiutare a rafforzare la sicurezza su larga scala, ma sollevano anche nuovi rischi di doppio uso che richiedono un’implementazione attenta.
— Portavoce ufficiale OpenAI
“Rischi di doppio uso”.
In parole povere: stiamo mettendo in circolazione un potenziale hacker automatizzato.
La strategia di mitigazione? Limitare l’accesso alle funzioni più potenti solo a chi paga di più o ha le credenziali giuste. Si crea così una casta digitale: le grandi corporation avranno accesso agli strumenti di difesa (e offesa) più sofisticati, mentre il piccolo sviluppatore o la PMI si dovranno accontentare della versione “sicura” (leggi: depotenziata), pur continuando a fornire i propri dati per il perfezionamento del modello “Elite”.
Inoltre, sotto la lente del GDPR, l’uso di questi agenti su dati personali sensibili – spesso presenti nei database di test o nei log che gli sviluppatori inavvertitamente danno in pasto all’IA – rappresenta un incubo di compliance.
Se l’IA “agisce” e non si limita a “suggerire”, chi è il responsabile del data breach?
L’utente che ha cliccato “accetta” o l’azienda che ha fornito un agente difettoso?
L’economia della dipendenza
Non possiamo ignorare il fattore economico. Questi modelli costano una fortuna in termini di inferenza. Con prezzi che sfiorano i 14 dollari per milione di token in output, l’obiettivo di OpenAI non è la beneficenza, ma la creazione di una dipendenza infrastrutturale.
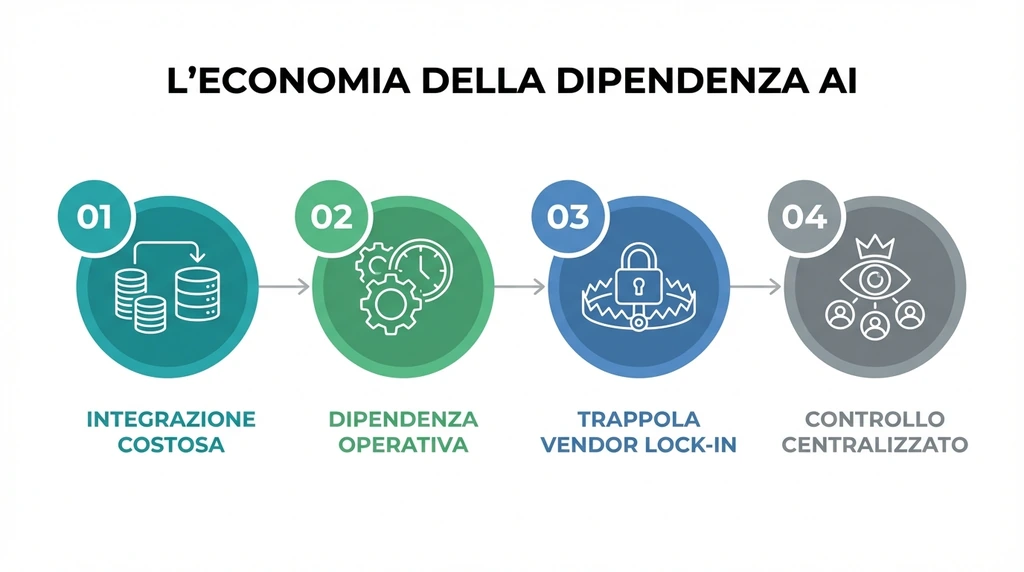
Recentemente l’azienda ha annunciato i modelli base GPT-5.2 con versioni ottimizzate per il coding, spianando la strada a un ecosistema dove ogni azione dello sviluppatore è mediata – e tariffata – da un’intelligenza artificiale.
Aumentare i limiti oggi serve a integrare questi strumenti nei flussi di lavoro aziendali domani. Una volta che un team di sviluppo si abitua alla velocità di un agente che scrive boilerplate e test, tornare indietro diventa impossibile.
È lì che scatta la trappola del vendor lock-in.
In parallelo, stiamo pilotando l’accesso fidato solo su invito alle capacità future e modelli più permissivi per professionisti e organizzazioni controllate focalizzate sulla cybersecurity difensiva. Crediamo che questo approccio all’implementazione bilancerà l’accessibilità con la sicurezza.
— Portavoce ufficiale OpenAI
La “sicurezza” citata qui sembra riferirsi più alla sicurezza del loro monopolio che alla vostra privacy.
Creare un club esclusivo di “professionisti controllati” serve a mantenere il controllo sulle capacità più pericolose del modello, evitando che finiscano nelle mani sbagliate (o in quelle della concorrenza open source), ma centralizza anche un potere immenso nelle mani di una singola azienda privata californiana.
Mentre ci prepariamo a salutare il 2025, il “regalo” di OpenAI ci ricorda che nel capitalismo della sorveglianza non c’è tregua, nemmeno a Capodanno. Stiamo addestrando le macchine che scriveranno il codice del futuro, ma stiamo anche, forse inavvertitamente, scrivendo la fine della nostra privacy digitale, un prompt alla volta.
La vera domanda per il 2026 non è quanto sarà potente l’IA, ma quanto controllo avremo ancora noi su ciò che abbiamo costruito.
Siete sicuri di voler passare la vigilia a regalare i vostri dati a Sam Altman?


