
Nvidia acquisisce Groq: Una mossa da 20 miliardi per dominare l’inferenza AI
Nvidia acquisisce Groq: una mossa da 20 miliardi per dominare l’inferenza AI e integrare l’architettura a bassa latenza delle LPU
C’è una certa ironia nel fatto che l’annuncio più sismico per l’architettura dei semiconduttori dell’ultimo decennio arrivi mentre il resto del mondo è impegnato a scartare regali.
Ma la Silicon Valley non dorme mai, e Jensen Huang, CEO di NVIDIA, ha appena depositato sotto l’albero un pacchetto da 20 miliardi di dollari che cambia radicalmente la geometria del calcolo AI.
Non si tratta della solita acquisizione per inglobare un concorrente e spegnerne la luce; la mossa su Groq è chirurgica, tecnicamente affascinante e politicamente astuta.
Ufficialmente, Groq ha annunciato un accordo di licenza non esclusiva con Nvidia per la sua tecnologia di inferenza, mantenendo nominalmente la propria indipendenza operativa.
In pratica, però, stiamo assistendo a un trapianto di organi vitali: Nvidia si porta a casa la proprietà intellettuale e, soprattutto, il team di ingegneri guidato dal fondatore Jonathan Ross, lasciando a GroqCloud il compito di continuare a esistere come entità di servizio.
Per chi scrive codice e ottimizza pipeline di Machine Learning, questo non è un semplice affare finanziario: è la confessione implicita che l’architettura GPU, per quanto potente, aveva un tallone d’Achille che solo un design radicalmente diverso poteva proteggere.
L’eleganza deterministica contro la forza bruta
Per capire perché Nvidia abbia speso una cifra tale — tre volte superiore all’acquisizione di Mellanox — bisogna guardare sotto il cofano.
Le GPU di Nvidia sono mostri di parallelismo, progettate originariamente per renderizzare pixel e poi adattate brillantemente al calcolo matriciale necessario per l’addestramento (training) dei modelli AI.
Tuttavia, l’inferenza — ovvero il momento in cui l’AI risponde alla domanda dell’utente — richiede qualcosa di diverso: latenza minima e prevedibilità assoluta.
Groq ha costruito le sue LPU (Language Processing Unit) su un principio di determinismo quasi ossessivo.
A differenza delle GPU, che usano cache complesse, arbiter di memoria e logiche di scheduling dinamico che introducono micro-ritardi imprevedibili, l’architettura di Groq è un “single core” gigante dove il compilatore decide in anticipo esattamente dove si troverà ogni singolo bit di dati in ogni ciclo di clock.
È la differenza tra gestire il traffico con semafori intelligenti (GPU) e avere un treno che passa al secondo esatto prestabilito (LPU).
Questa eleganza tecnica ha permesso a Groq di offrire token-per-secondo irraggiungibili per l’hardware tradizionale sui Large Language Models.
Nvidia lo sapeva.
E sapeva che per dominare non solo la creazione delle AI (training), ma anche la loro esecuzione quotidiana (inference), aveva bisogno di quella tecnologia.
La logica strategica per NVIDIA è chiara: integrare l’architettura di inferenza a bassa latenza di Groq nella fabbrica AI di NVIDIA rafforza significativamente la sua posizione lungo l’intero stack di calcolo AI, dall’addestramento all’inferenza.
— Alex Davis, CEO di Disruptive (investitore principale in Groq)
Una “acquihire” da venti miliardi
Il vero valore di questo accordo, tuttavia, risiede probabilmente più nel silicio biologico che in quello sintetico.
Jonathan Ross non è un nome qualunque: è l’ingegnere che a Google aveva creato le TPU (Tensor Processing Unit), prima di andarsene frustrato dalla burocrazia di Mountain View per fondare Groq. Riportare lui e il suo team sotto l’ala di un gigante significa neutralizzare l’unica vera alternativa architetturale che stava guadagnando trazione reale.
Le implicazioni tecniche sono vaste.
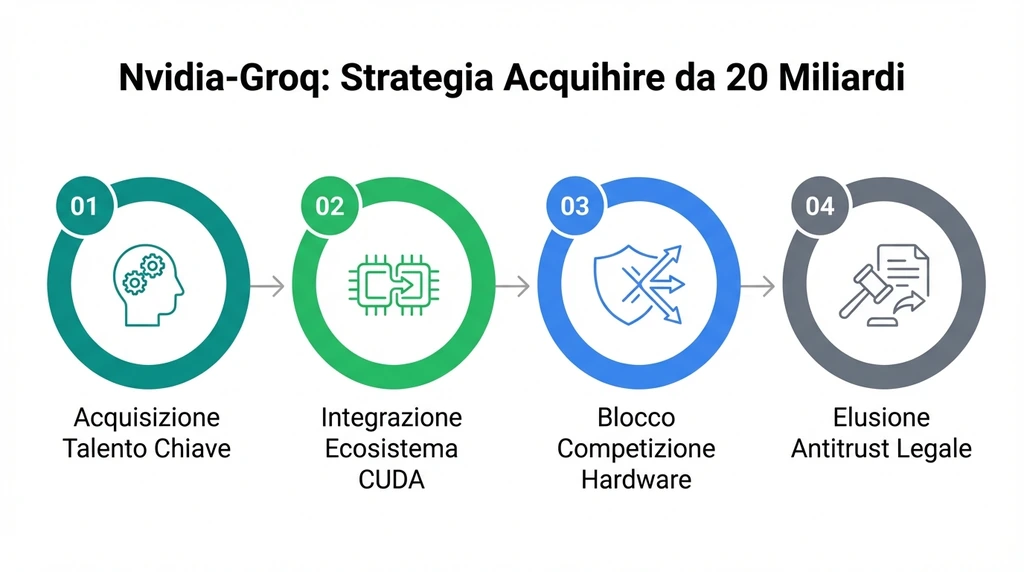
Immaginate un futuro stack Nvidia dove i modelli vengono addestrati su cluster di GPU Blackwell per la loro potenza bruta, e poi serviti in produzione su moduli basati su IP Groq, integrati nello stesso ecosistema CUDA che tutti noi sviluppatori siamo (più o meno volentieri) costretti a usare.
Nvidia acquisisce gli asset e il talento chiave per una cifra record di 20 miliardi di dollari, un prezzo che si spiega solo con la necessità di chiudere il cerchio dell’hardware AI prima che AMD o Intel possano proporre alternative credibili come il MI350 o Gaudi 3.
Ma c’è un dettaglio che rende questa operazione un capolavoro di ingegneria legale, non solo informatica.
La struttura dell’accordo evita deliberatamente la fusione completa.
Lasciando “in vita” GroqCloud come fornitore di servizi indipendente sotto la guida del nuovo CEO Simon Edwards, Nvidia tenta di schivare i proiettili dell’antitrust. È una lezione imparata a caro prezzo dopo il fallimento dell’acquisizione di Arm: se non puoi comprare l’azienda intera senza che la FTC o l’Unione Europea ti blocchino, compra solo quello che ti serve (la tecnologia e le persone) e lascia lo scheletro societario al suo destino.
Il paradosso della competizione simulata
Questa manovra pone interrogativi seri sul futuro dell’open ecosystem.
Groq rappresentava una speranza per chi cercava performance senza il “lock-in” di Nvidia. Sebbene l’accordo sia etichettato come “licenza non esclusiva”, la realtà del mercato è spesso meno sfumata dei contratti legali.
Con il team originale di ingegneri ora a libro paga di Nvidia, chi svilupperà la prossima generazione di LPU per GroqCloud?
Un’azienda di hardware svuotata dei suoi progettisti hardware è come un browser web senza motore di rendering: un’interfaccia vuota.
Questo accordo è strutturato come un accordo di licenza tecnologica non esclusiva piuttosto che come un’acquisizione tradizionale dell’intera azienda, permettendo a Groq di continuare a gestire la sua attività GroqCloud in modo indipendente.
— Jonathan Ross, Fondatore e CEO (uscente) di Groq
La comunità degli sviluppatori guarda con scetticismo a questa “indipendenza”.
Senza il motore propulsivo dell’innovazione interna, GroqCloud rischia di diventare un semplice rivenditore glorificato, mentre la vera magia dell’ottimizzazione deterministica verrà fusa nel silicio Nvidia delle prossime generazioni.
Gli analisti vedono questa mossa come un tentativo di consolidare il dominio nell’inferenza AI, blindando il mercato in un momento critico in cui la domanda si sta spostando dall’addestramento dei modelli al loro utilizzo pratico su vasta scala.
Siamo di fronte a un consolidamento che tecnicamente ha senso — l’unione tra la flessibilità delle GPU e la precisione delle LPU è il Santo Graal dell’hardware AI — ma che restringe pericolosamente il campo di gioco.
La domanda che rimane sospesa, mentre i regolatori iniziano a studiare le carte in questi giorni di festa, non è se la tecnologia funzionerà (funzionerà eccome), ma se tra cinque anni avremo ancora una scelta su quale hardware far girare i nostri container.
Nvidia ha appena comprato il tempo, la velocità e, forse, l’assenza di concorrenza.
Resta da vedere se il prezzo pagato, per quanto astronomico, non si rivelerà un affare per aver comprato il monopolio de facto sull’intelligenza delle macchine.


