
Reddit vs Perplexity AI: La Battaglia per il Futuro dei Dati Online
La disputa legale tra Reddit e Perplexity AI ridefinisce l’accesso alle informazioni online, sollevando interrogativi sul futuro della creazione di contenuti e dei modelli di business digitali
Siamo alla fine di un 2025 che ha ridefinito le regole del gioco digitale, e la battaglia legale tra Reddit e Perplexity AI ne è diventata l’emblema perfetto. Non stiamo parlando di una semplice scaramuccia tra avvocati in giacca e cravatta, ma di uno scontro ideologico e tecnico che determinerà come (e se) potremo accedere alle informazioni online nel prossimo decennio.
Da una parte c’è la “piazza” di discussione più grande del mondo, che ha deciso di chiudere i cancelli; dall’altra c’è il motore di risposta che promette di liberarci dalla tirannia dei link blu, ma che per farlo ha bisogno di nutrirsi dei contenuti altrui.
Tutto è precipitato lo scorso ottobre, quando Reddit ha trascinato Perplexity nel distretto federale di New York. L’accusa non è leggera: furto su scala industriale.
Ma per capire la gravità della situazione, bisogna guardare oltre la carta bollata e osservare la tecnologia che c’è dietro. Perplexity non è solo un “altro Google”; è uno strumento che sintetizza risposte dirette, rendendo spesso superfluo cliccare sulla fonte originale. Fantastico per noi utenti che vogliamo risposte rapide, devastante per chi quelle risposte le ha scritte e ospitate sperando in una visita e in una visualizzazione pubblicitaria.
Tuttavia, c’è un dettaglio da spy-story in questa faccenda che merita di essere raccontato.
Reddit non si è limitata a denunciare; ha teso una trappola.
La trappola del “honeypot” e il riciclaggio di dati
Per dimostrare che Perplexity stava “rubando” i dati nonostante i divieti espliciti, gli ingegneri di Reddit hanno creato quello che in gergo tecnico si chiama un honeypot.
Immaginate un post invisibile agli utenti normali, nascosto nei meandri del codice, ma accessibile ai bot che scansionano la rete. Reddit ha bloccato ufficialmente i crawler di Perplexity tramite il protocollo robots.txt (il cartello “non entrare” del web), ma quel post esca è finito comunque nelle risposte fornite dall’AI.
Come è successo? Qui la tecnologia si fa affascinante e inquietante allo stesso tempo. Secondo l’accusa, Perplexity non avrebbe sfondato la porta principale, ma sarebbe entrata dalla finestra, o meglio, avrebbe pagato qualcuno per farlo. Reddit accusa la startup di aver aggirato le protezioni tecniche tramite bot e web crawler utilizzando servizi di terze parti e proxy anonimi.
In pratica, Perplexity è accusata di fare “data laundering”, riciclaggio di dati.
Invece di scansionare Reddit direttamente (cosa che le era stata vietata), avrebbe utilizzato i risultati memorizzati nella cache di Google o si sarebbe appoggiata a fornitori di dati come Oxylabs e SerpApi. Questi intermediari agiscono come “prestanome digitali”, mascherando l’origine della richiesta e permettendo all’AI di assorbire migliaia di discussioni umane per addestrare i propri modelli.
Questa pratica distrugge il modello di business di Reddit, violando i diritti di proprietà intellettuale e parassitando il valore creato dai nostri utenti.
— Estratto dalla denuncia di Reddit, Inc.
Se questo viene confermato, il precedente è enorme: un’azienda di AI può essere ritenuta responsabile per i dati che ottiene indirettamente?
La risposta potrebbe cambiare l’architettura stessa del web.
Il valore dell’oro digitale e i contratti miliardari
Per capire perché Reddit sia così furiosa, bisogna seguire i soldi. Nel 2025, i dati generati dagli umani (i vostri commenti sulle serie TV, le recensioni di gadget, i consigli legali su r/legaladvice) sono diventati il petrolio dell’era dell’intelligenza artificiale.
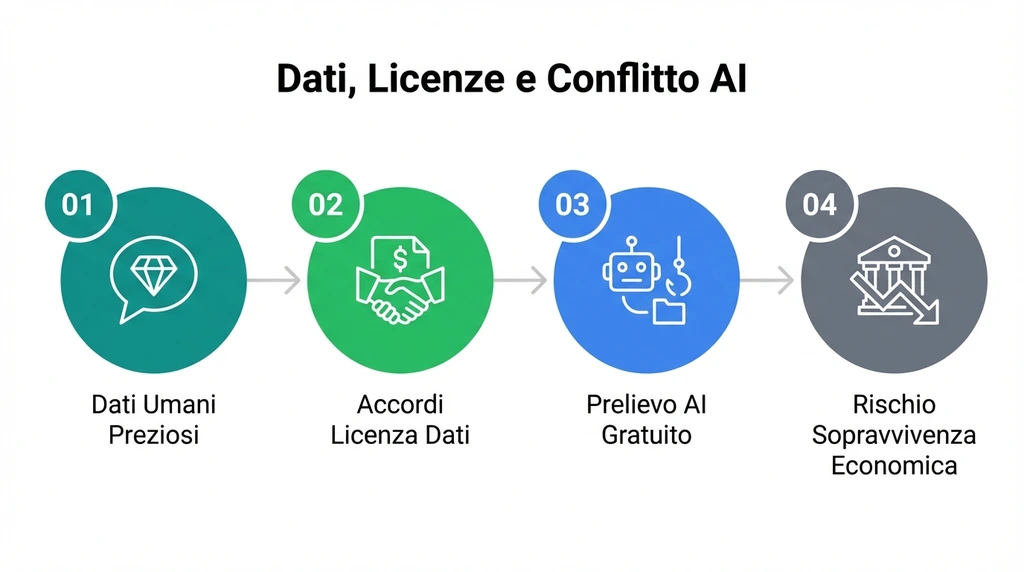
Le AI non possono “pensare” dal nulla; hanno bisogno di esempi. E Reddit è la miniera d’oro più pura di conversazioni umane autentiche.
L’azienda non è contraria all’AI per principio, anzi. Il problema è che vuole essere pagata. Reddit ha recentemente stretto accordi di licenza lucrativi con giganti come Google e OpenAI, valutati circa 60 milioni di dollari all’anno, per permettere loro di usare legalmente i suoi dati.
Quando Perplexity arriva e prende lo stesso materiale gratis, aggirando i blocchi, non sta solo facendo un dispetto; sta svalutando attivamente quegli accordi commerciali. Se Google paga 60 milioni e Perplexity zero, perché Google dovrebbe continuare a pagare?
È una questione di sopravvivenza economica.
Per noi utenti finali, questo scenario apre un dilemma: amiamo strumenti come Perplexity perché sono gratuiti ed efficienti, ma se la loro esistenza distrugge le piattaforme che creano i contenuti da cui dipendono, cosa resterà da leggere tra cinque anni?
La difesa del “fair Use” e l’effetto domino
Perplexity, dal canto suo, non è rimasta in silenzio. La loro difesa si basa su un concetto cardine del diritto americano: il Fair Use.
Sostengono che l’indicizzazione e la sintesi di informazioni pubblicamente accessibili non sia furto, ma un servizio trasformativo. Dopotutto, un motore di ricerca tradizionale fa la stessa cosa: legge il sito e ti mostra un’anteprima. Perplexity fa solo un passo in più: ti dà la risposta completa.
Ma quel “passo in più” è proprio il punto critico. Se l’AI mi dà la risposta completa, io non visito mai il sito originale. Il creatore del contenuto perde traffico, perde entrate pubblicitarie, e alla fine smette di creare.
La tensione era nell’aria da mesi: Reddit ha ignorato una diffida formale emessa lo scorso maggio, in cui si intimava a Perplexity di cessare immediatamente le attività di scraping non autorizzato. Il fatto che le citazioni di Reddit su Perplexity siano aumentate di quaranta volte dopo quella diffida è stato interpretato come una dichiarazione di guerra aperta.
Non è solo Reddit a pensarla così. Anche editori tradizionali come Dow Jones (Wall Street Journal) hanno avviato cause simili. Siamo di fronte a un fronte comune di creatori di contenuti contro gli aggregatori di AI.
Se i tribunali dovessero dare ragione a Reddit, l’era dell’addestramento AI “selvaggio” e a costo zero finirebbe di colpo.
Le startup di AI si troverebbero costrette a pagare licenze esorbitanti o a chiudere, lasciando il campo solo ai giganti che possono permetterselo.
La tecnologia corre veloce, ma la legge sta cercando di metterle le briglie. La domanda che dobbiamo porci, mentre usiamo entusiasti i nostri assistenti virtuali, è scomoda ma necessaria: siamo disposti a sacrificare l’ecosistema umano del web pur di avere risposte istantanee da una macchina?
Perché se l’AI cannibalizza chi la nutre, presto potremmo trovarci con motori di ricerca potentissimi che non hanno più nulla di nuovo da trovare.


